Comment calculer le nombre de mots d'un bloc de texte avec Screaming Frog ?

Table des matières
Après avoir vu comment identifier les balises Hn vides avec Screaming Frog, voici une nouvelle astuce consacrée au meilleur crawler du marché (selon moi).
Un de mes besoins récurrents en phase d'audit SEO, ou simplement d'analyse, c'est de savoir combien de mots se trouvent dans un élément HTML donné.
Exemple : quelle est la longueur du bloc de texte en-dessous (ou au-dessus) des pages catégories de mon site e-commerce ?
Avec Screaming Frog, on a bien quelques infos sur le nombre de mots, mais uniquement à l'échelle globale de la page (Internal > Word Count).
Chaque site étant différent, il faut donc passer par une extraction personnalisée pour connaître le nombre de mots à l'intérieur d'un nœud précis.
Peut-on utiliser les regex ?
Utiliser une expression régulière pour ce type d'opérations serait possible mais exigerait un double traitement :
- la récupération des mots dans Screaming Frog (avec le pattern \w par exemple)
- le comptage du nombre d'occurrences trouvées pour ce pattern
On le voit, la phase 2 nécessiterait de passer par un deuxième outil. Or, je souhaite faire cela en une seule passe.
Voyons donc la 2ème option.
XPath à la rescousse !
Et oui, une nouvelle fois, on va faire appel à XPath.
En combinant 3 fonctions : string-length, translate et normalize-space.
L'idée est simple : les mots d'une phrase étant séparés par des espaces, on va compter le nombre d'espaces. Par extrapolation, cela nous donnera le nombre de mots. On ajoutera 1 pour ne pas oublier le dernier mot.
OK, mais comment faire ?
1ère étape
D'abord, on va compter le nombre total de caractères à l'intérieur du contenu, espace inclus.
Ce qui donne : string-length(normalize-space(//*[@class="classe-de-mon-element"]))
La fonction normalize-space me permet ici de transformer les éventuels doubles espaces en espace unique et de supprimer les espaces de début ou de fin de chaîne superflus, afin de ne pas biaiser le résultat.
La fonction string-length quant à elle me retourne le nombre de caractères.
2ème étape
Puis, on va faire la même chose, mais cette fois en supprimant les espaces.
Ce qui donne string-length(translate(normalize-space(//*[@class="classe-de-mon-element"]), " ", "").
La fonction translate me permet ici de remplacer chaque espace par une chaîne vide.
3ème étape
On va soustraire le résultat de la 2ème étape au résultat de la 1ère étape afin, tu l'auras compris, de compter le nombre d'espaces.
Enfin, on va rajouter +1 car le dernier mot n'étant plus séparé par un espace, il n'est de base pas compté dans le total.
La requête finale
Voilà donc la requête à utiliser :
string-length(normalize-space(//[@class="classe-de-mon-element"])) - string-length(translate(normalize-space(//[@class="classe-de-mon-element"]),' ','')) +1Il faudra bien entendu que tu remplaces //*[@class="classe-de-mon-element"]) par l'élément HTML qui t'intéresse dans ton template de page.
Si je prends l'exemple de SEO Memento et que je veux récupérer le nombre de mots de chaque article, j'utiliserai la requête XPath suivante :
string-length(normalize-space(//*[contains(@class, 'single-content')])) - string-length(translate(normalize-space(//*[contains(@class, 'single-content')]),' ','')) +1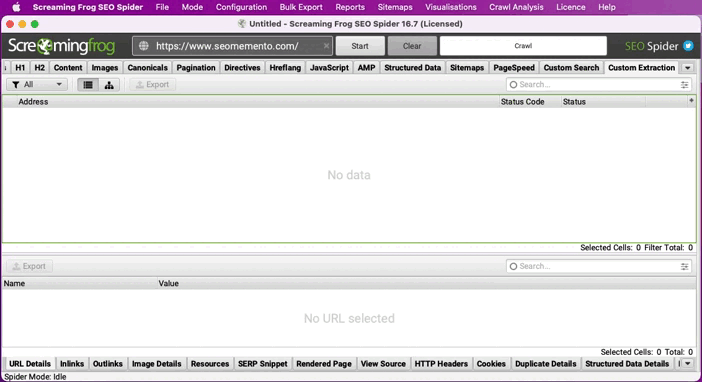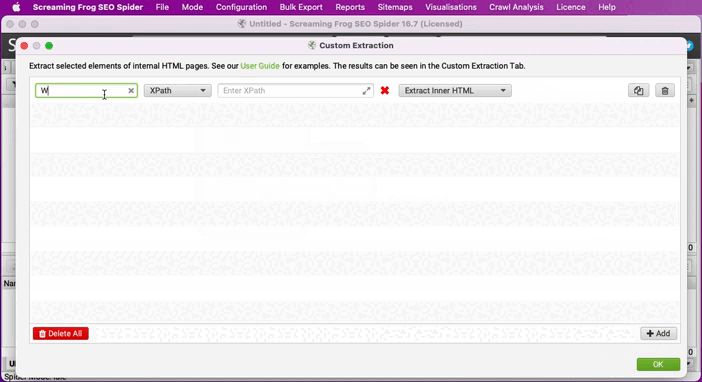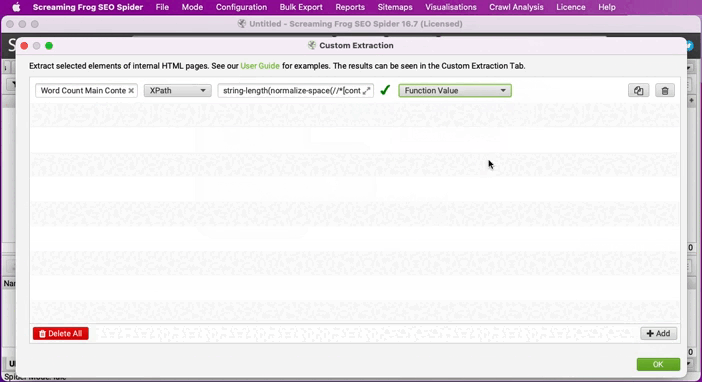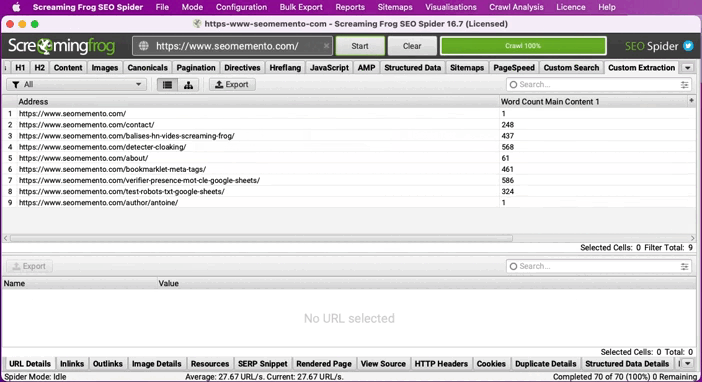
Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.