7 moyens simples de détecter un cloaking

Table des matières
Tout d'abord, un petit rappel de ce qu'est le cloaking. Dit simplement, c'est le fait d'afficher aux robots de Google, ou de tout autre moteur de recherche, un code HTML différent de celui qui sera envoyé aux autres clients.
Autrement dit, afficher une version différente d'une page web selon qui la demande, le moteur de recherche ou l'internaute.
Cette pratique est bien entendu contraire aux guidelines de Google.
Les motivations au cloaking peuvent être nombreuses :
- afficher un contenu optimisé à Google pour le faire ranker et rediriger l'internaute directement vers une page de vente ou vers un site partenaire en affiliation
- cacher des liens à Google pour mieux maîtriser la circulation du Pagerank interne
- empêcher un concurrent de remonter un réseau de sites, en affichant à Google une belle page de contenu avec le BL vers son money site, tout en renvoyant une page blanche ou un code 403, par exemple, aux internautes et aux outils d'analyse de backlinks
- etc.
Pour mettre en place un cloaking, il est possible d'utiliser :
- la détection de l'user-agent (aisément manipulable)
- la détection de l'IP (liste d'IP Googlebot dispo ici au format JSON)
- le reverse DNS
- la détection du support ou non des cookies par le client
Je ne m'étalerai pas plus aujourd'hui sur ces techniques, cela fera peut-être l'objet d'une prochaine newsletter.
Passons au coeur du sujet : comment faire pour détecter un cloaking ?
User-Agent Switcher for Chrome
Il s'agit d'un plugin Google Chrome qui permet de changer à la volée son user-agent lorsqu'on navigue sur le web.
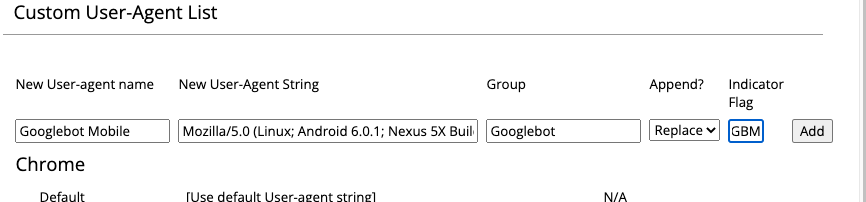
Voici la chaîne à utiliser si tu souhaites te faire passer pour Googlebot Mobile :
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Rends-toi dans les options du plugin pour ajouter ce nouvel UA.
Problème : si le site utilise un cloaking plus "costaud", à base de détection d'IP par exemple, tu ne pourras pas le détecter.
Le cache Google
Il suffit d'entrer la commande Google cache:http://example.com pour visualiser ce que Google a indexé.
Pour accéder directement à la source HTML en cache, rends-toi sur cette URL : http://webcache.googleusercontent.com/search?q=cache:http://example.com&strip=0&vwsrc=1.
Problème : si la page affiche en header HTTP la directive X-Robots-Tag: noarchive, ou en <head> la balise <meta name="robots" content="noarchive" />, le cache ne sera pas disponible.
Les outils de tests Google
C'est sûrement la façon de procéder la plus fiable : détourner les outils de test Google pour savoir ce que "voit" vraiment le robot quand il inspecte la page.
Dans cette optique, tu peux utiliser :
- AMP Validator : tu auras directement accès au code source reçu par Google
- Google Mobile Friendly Test : tu auras accès au code HTML et tu pourras visualiser le screenshot de la version "rendue" de la page
- PageSpeed Insights : en testant la vitesse de chargement d'une page, tu recevras en bonus un screenshot de la page telle qu'interprétée par Google
- Test My Site : même idée que l'outil précédent
Google Traduction
Pour terminer, une solution un peu plus insolite : Google Translate. Et oui, ce service de Google utilise les mêmes classes d'IP que Googlebot !
Rends-toi sur https://translate.google.fr/. Entre une URL dans le champ de gauche, puis clique sur le lien obtenu dans le champ de droite.
Et hop, te voilà sur la version potentiellement cloakée de la page. Avec un CTRL+U, tu pourras, en plus, vérifier ce qui se passe dans le code source.
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.