Vérification du contenu dupliqué avec Screaming Frog : attention au contenu "boilerplate"

Table des matières
La semaine derrière, j'ai suivi quelques unes des conférences de la SEO Garden Party organisée par Linksgarden.
J'ai notamment écouté avec beaucoup d'attention l'intervention de Sylvain Peyronnet sur le sujet de l'audit algorithmique.
Sylvain a évoqué la question de la duplication interne et a expliqué pourquoi il était judicieux de calculer à la fois un score de duplication AVEC les éléments de navigation et un score de duplication SANS les éléments de navigation.
En effet, si le score de duplication d'une page est plus fort avec la navigation que sans, ça signifie que la navigation crée la duplication et donc, que le contenu a besoin d'être étoffé.
De plus, Google est tout-à-fait capable de détecter les contenus boilerplate d'un site. Il est donc possible qu'il les ignore, partiellement ou entièrement.
Avec Screaming Frog, comme l'a rappelé Sylvain, il est assez simple d'ajuster les paramètres de crawl pour définir quel contenu doit être analysé.
Définir la zone de contenu
Première étape : aller dans Configuration > Content > Area.
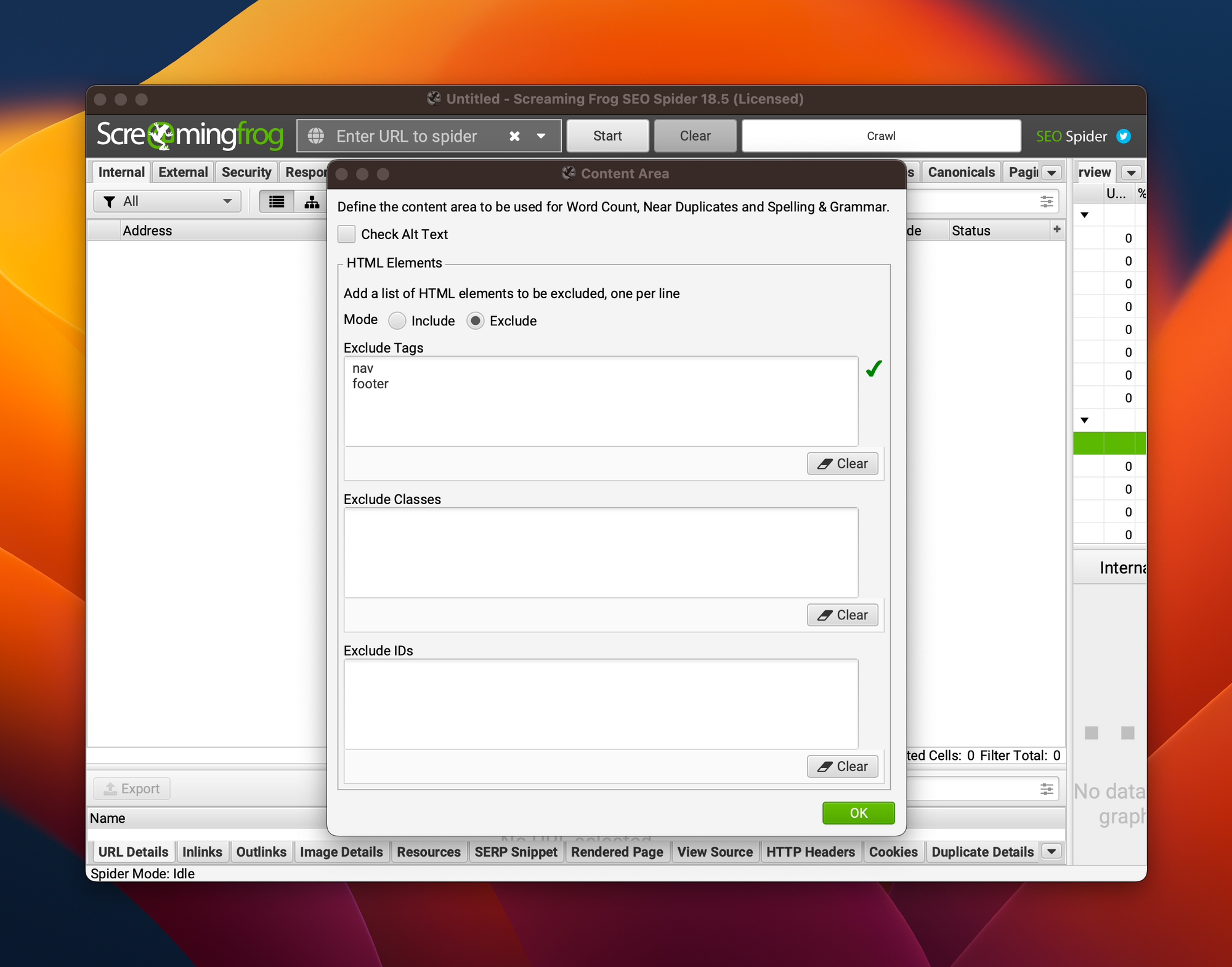
Puis vérifier que les zones les plus susceptibles de contenir des éléments textuels qui se répètent sont exclues (nav, aside, footer par exemple). Tu peux également jouer avec les classes et les ID CSS pour affiner.
Si ton site est un WordPress, je te conseille d'utiliser le mode "Include" en ajoutant simplement article dans la liste des tags.
La plupart des thèmes WordPress placent en effet le contenu principal dans cette balise (tu peux aussi te servir des classes CSS post et page).
Activer le near duplicate
Maintenant, il faut demander à Screaming Frog d'activer la recherche de near duplicates.
Cette opération est assez coûteuse car elle nécessite de stocker le HTML pour réaliser l'analyse post crawl.
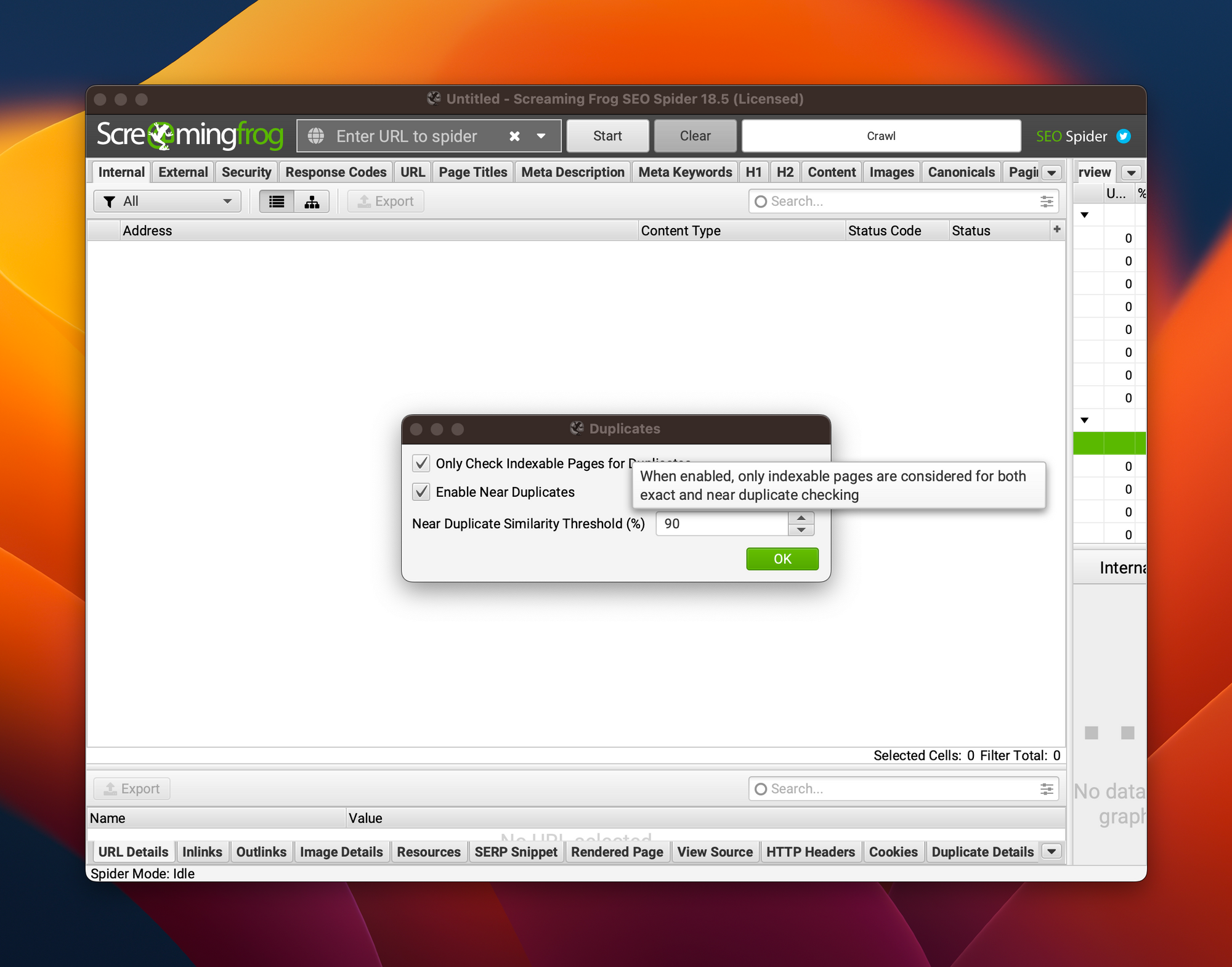
Si ton site est volumineux, mieux vaut donc passer en mode "Database Storage" pour éviter de saturer la RAM.
Tu peux également régler le seuil à partir duquel tu considères que les contenus sont similaires. Par défaut, c'est 90% mais je le fixe généralement à 85%.
Si tu souhaites approfondir le sujet, tu peux lire cet article de Screaming Frog.
Lancer l'analyse
Une fois que le crawl est terminé, il ne reste plus qu'à lancer l'analyse en te rendant dans Crawl Analysis > Start.
Les résultats apparaissent alors dans l'onglet Content :
- colonne No. Near Duplicates : le nombre de near duplicates détectés
- colonne Closest Similarity Match : l'URL présentant le contenu le plus similaire à l'URL inspectée
Dans le cas du site seomemento.com, voici les réglages que j'ai utilisés :
- zone de contenu : balise
main
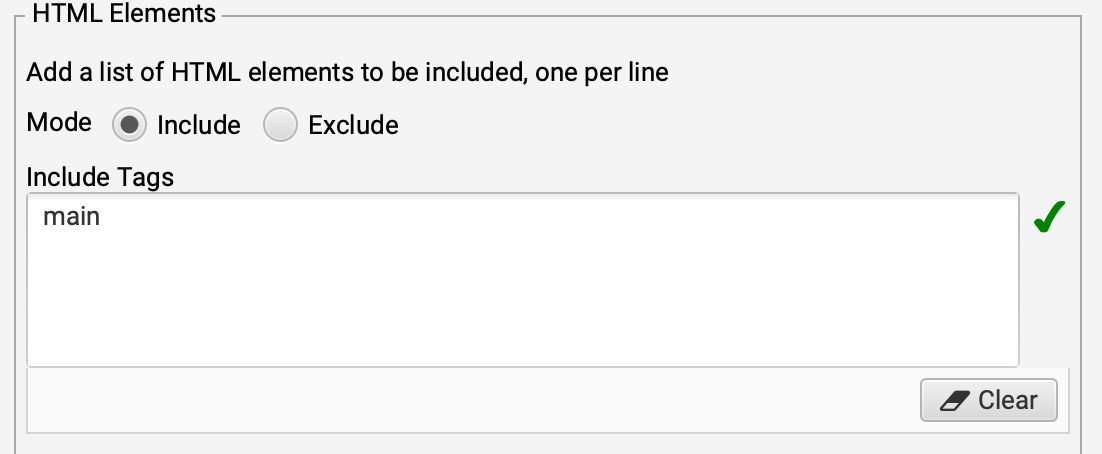
- seuil de similarité : 85%
Et voici ce que ça donne ↓
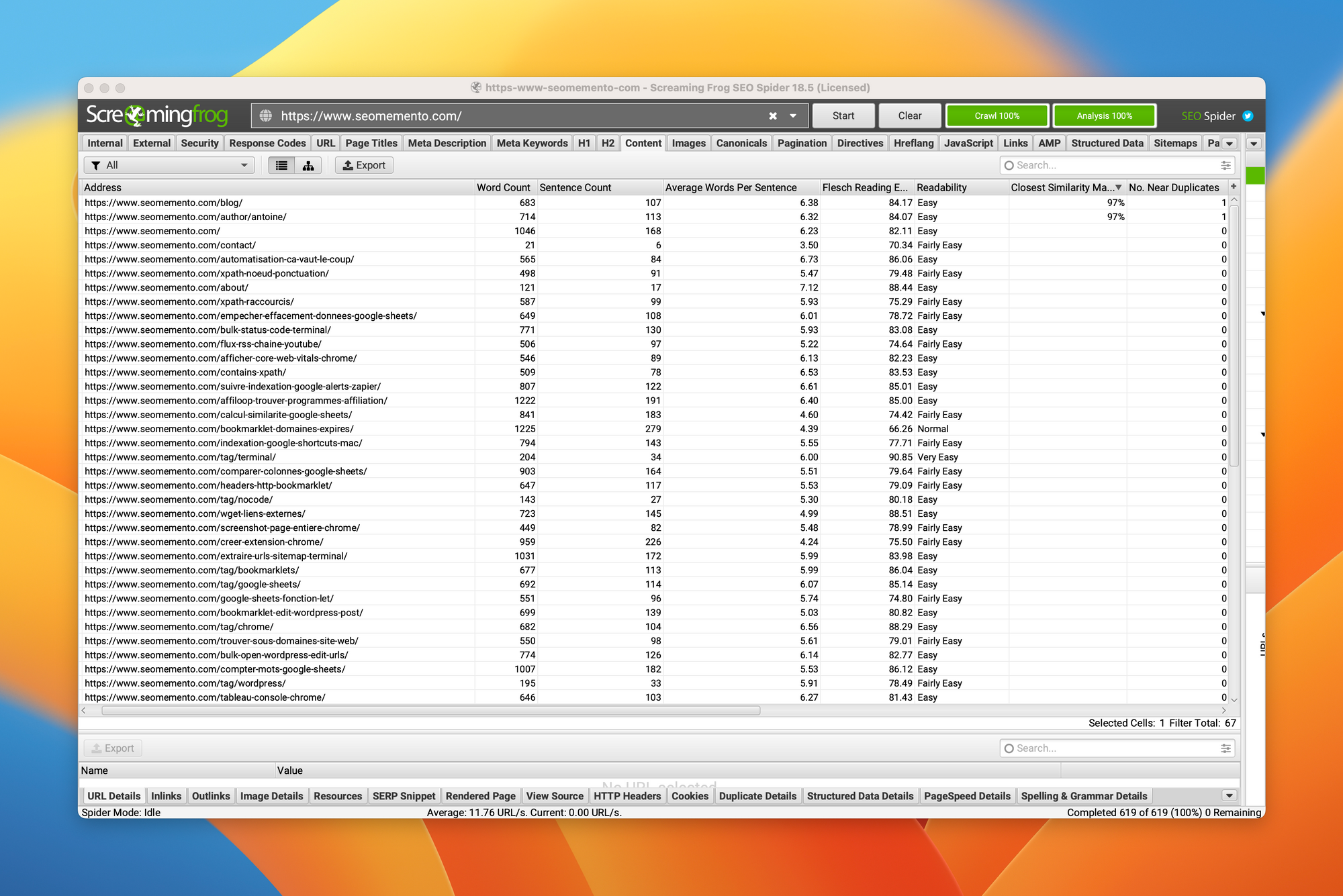
Les pages présentant le plus de similarité sont la page blog et la page auteur.
Assez logique puisqu'elles listent toutes les deux les dernières éditions de la newsletter.
En revanche, pas de problème de contenu dupliqué à l'échelle des articles. Cool :)
Et voilà, j'espère que ce petit tuto te sera utile pour tes prochains crawls.
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.