
Comment extraire le root domain d'une liste d'URLs en bulk ? (OUTIL GRATUIT)

Table des matières
C'est un problème qui revient régulièrement dans la sphère SEO : comment extraire le domaine racine d'une URL ?
J'ai souvent vu passer des tweets à ce sujet, comme ici ou là.
Nicolas de Tremplin Numérique en a même parlé dernièrement dans sa conférence sur les sites Google News.
Les solutions proposées à chaque fois fonctionnent... sauf cas particuliers :
- s'il y a plusieurs sous-domaines dans l'URL
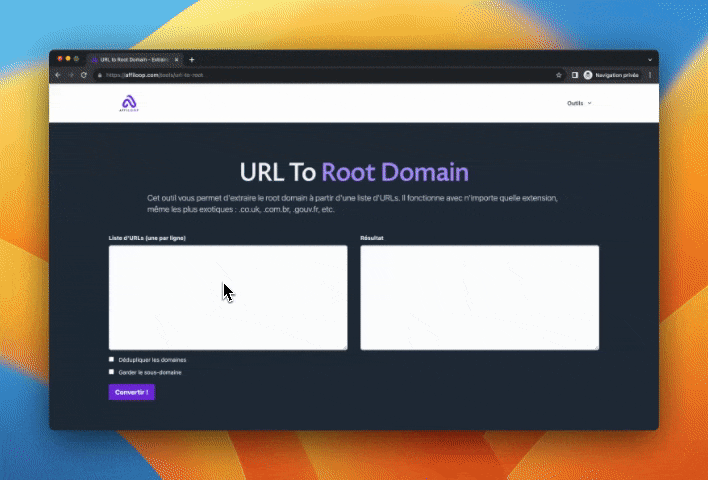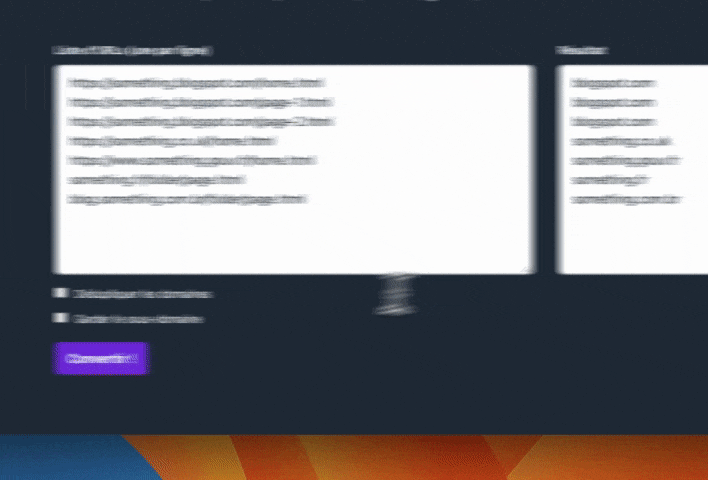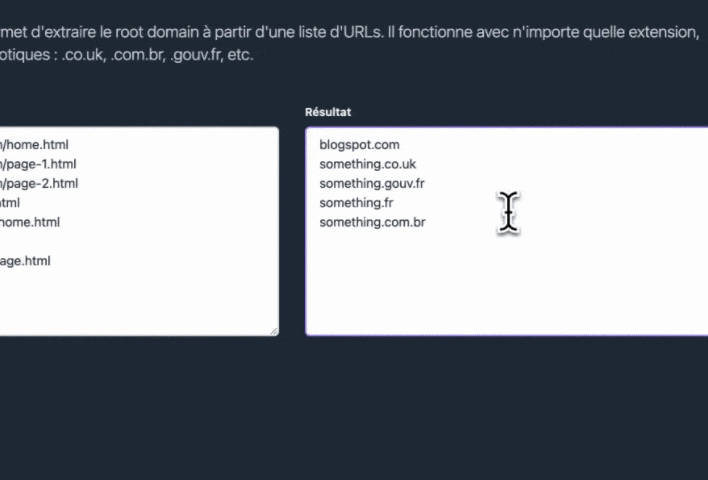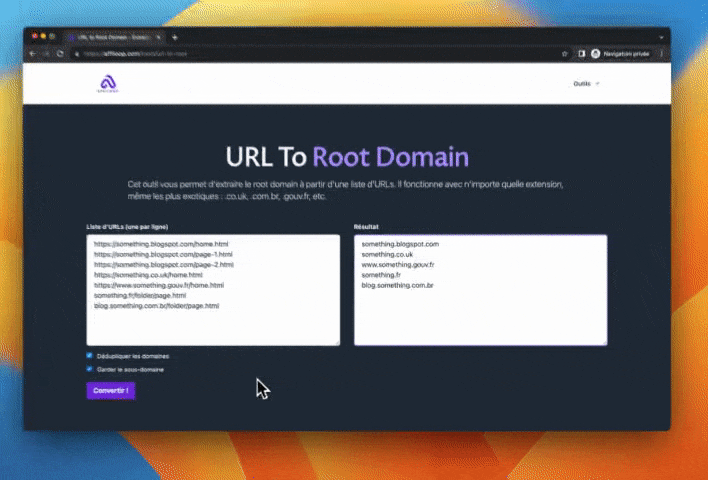
- si le nom de domaine se termine par un TLD exotique comme
.com.brou.gouv.fr - si le domaine est privé, comme blogspot.com
- etc.
Et sur internet, la plupart des outils que j'ai testés présentent les mêmes limites.
Du coup, ça m'a donné envie de me (re)pencher sur le sujet et de créer un outil en ligne qui fonctionne "à tous les coups".
Il est disponible gratuitement ici : https://affiloop.com/tools/url-to-root
Il s'appuie sur la Public Suffix List, un projet à l'initiative de Mozilla dont l'objectif est de répertorier l'ensemble des extensions de noms de domaines disponibles.
Pour utiliser l'outil, c'est simple :
- tu entres une liste d'URLs
- tu cliques sur "dédupliquer les domaines" si tu veux supprimer les doublons
- tu cliques sur "garder le sous-domaine" si tu as besoin de conserver les sous-domaines (exemple : toto.blogspot.com)
- tu cliques sur le bouton "convertir"
Et hop. Plus qu'à copier les résultats.
Si tu veux aller plus loin sur le sujet, tu peux aussi :
- tester la regex donnée par Walid (Light On SEO)
- relire mon article sur le parsing d'URL avec Google Sheets
- jeter un coup d'oeil à Gadgeto (y'a un tool complet pour triturer les URLs)
Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.



){kind=link}