Comment suivre ses positions Google avec Screaming Frog ?

Table des matières
L'astuce du jour est une nouvelle fois consacrée à la grenouille qui hurle Screaming Frog.
Je vais te montrer comment tu peux te servir de ce logiciel pour suivre ton positionnement sur Google.
Oui, tu as bien entendu, ton positionnement. Avec un peu d'huile de coude, c'est tout à fait possible.
Pour ma part, j'utilise cette méthode dans le cadre d'analyses ponctuelles, quand le volume de mots-clés à checker est peu important.
Cela évite l'abonnement à un outil tiers ou à une API et c'est, je dois le dire, très appréciable.
Trêve de blabla, entrons dans le vif du sujet.
1ère étape : configurer Screaming Frog pour scraper Google
Pour être sûr de ne pas être bloqué par le CAPTCHA de Google, il faut se rapprocher le plus possible du comportement "standard" d'un internaute.
Je vais donc :
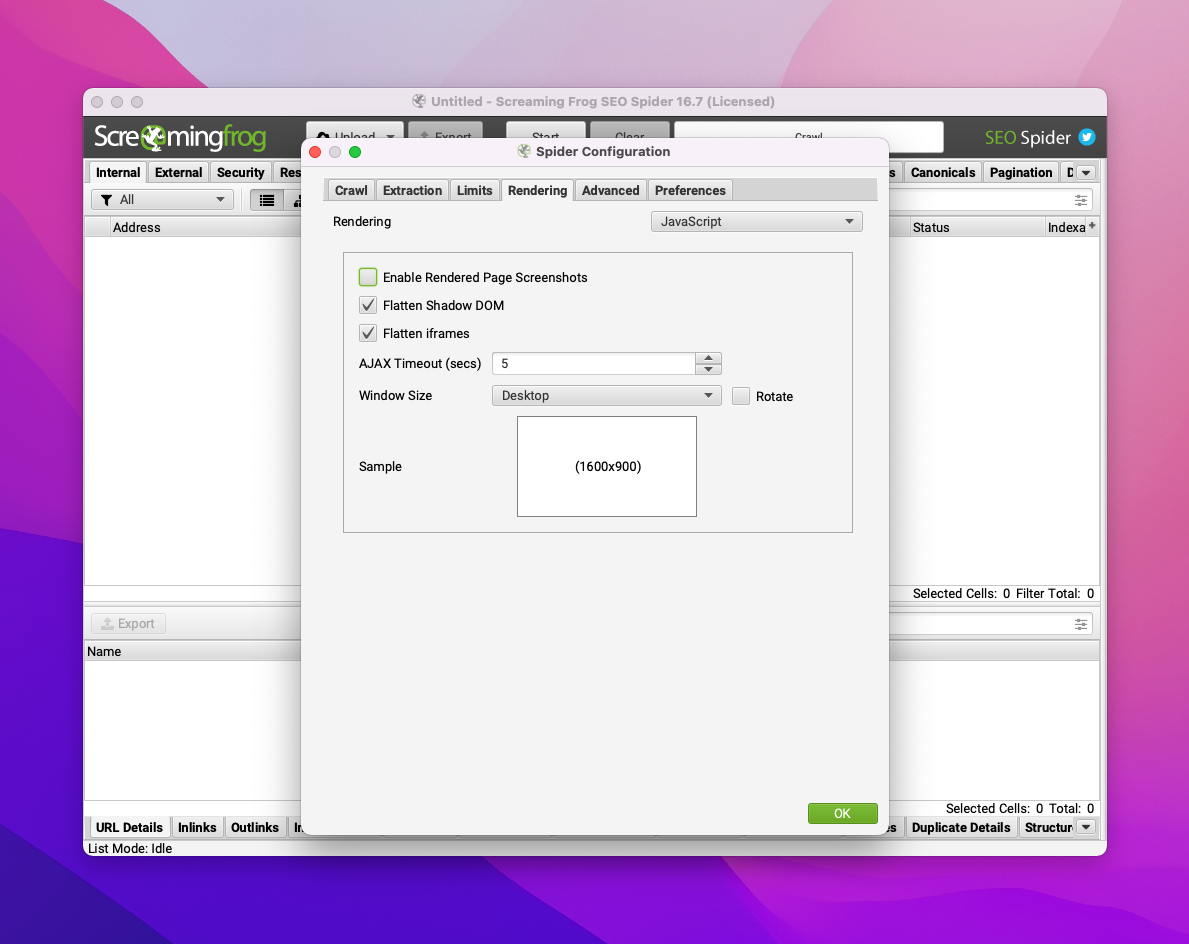
- activer le rendering JavaScript
- modifier la taille du viewport (Window Size = "Desktop")
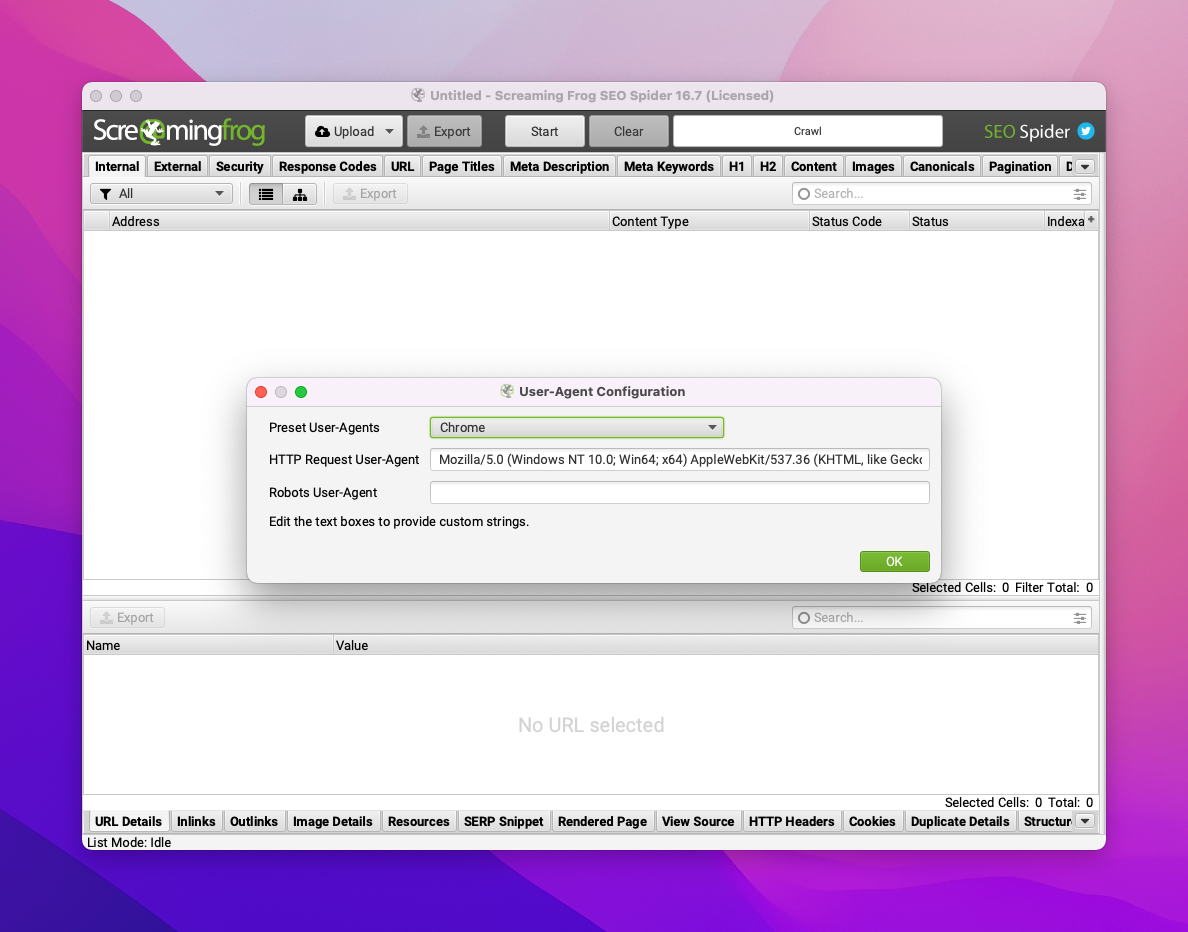
- changer le user agent (Chrome)
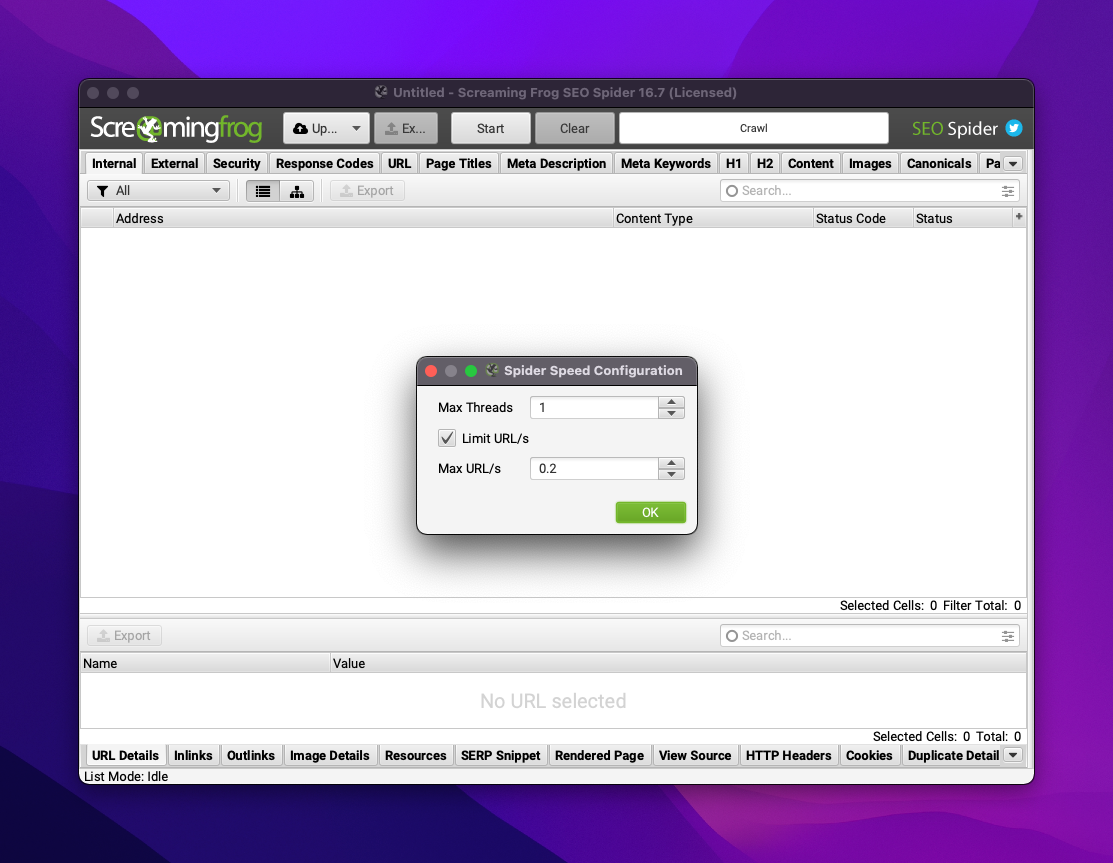
- réduire la vitesse de crawl (1 thread et 0,2 URL/s)
2ème étape : créer la liste des URLs de recherche Google
Comme je vais utiliser Screaming Frog en mode liste, en interrogeant les URLs de résultats de recherche Google, il faut bien entendu préparer ces URLs en y incorporant les mots-clés à suivre.
Pour ce faire, je vais utiliser Google Sheets, en concaténant l'URL de recherche Google avec le mot-clé recherché.
La formule est la suivante :
="https://www.google.fr/search?q="&ENCODEURL(A2)&"&pws=0&num=100"Le paramètre &pws=0 permet de s'assurer que les résultats ne seront pas personnalisés, tandis que le paramètre &num=100 permet d'afficher 100 résultats.
3ème étape : créer l'expression XPath affichant la position de ton site
C'est ici que ça devient intéressant.
Pour l'exemple, je vais prendre mon site perso www.antoine-brisset.com.
L'idée, c'est de déterminer quelle est sa position dans les résultats Google sur un panel de mots-clés.
Pour ce faire, je vais détourner l'utilisation des fonctions XPath count et boolean.
Je vais en effet compter le nombre de résultats qui se situent, dans la SERP, avant mon propre site. Et je vais ajouter 1 pour obtenir la position de mon propre site, seulement si mon site est présent.
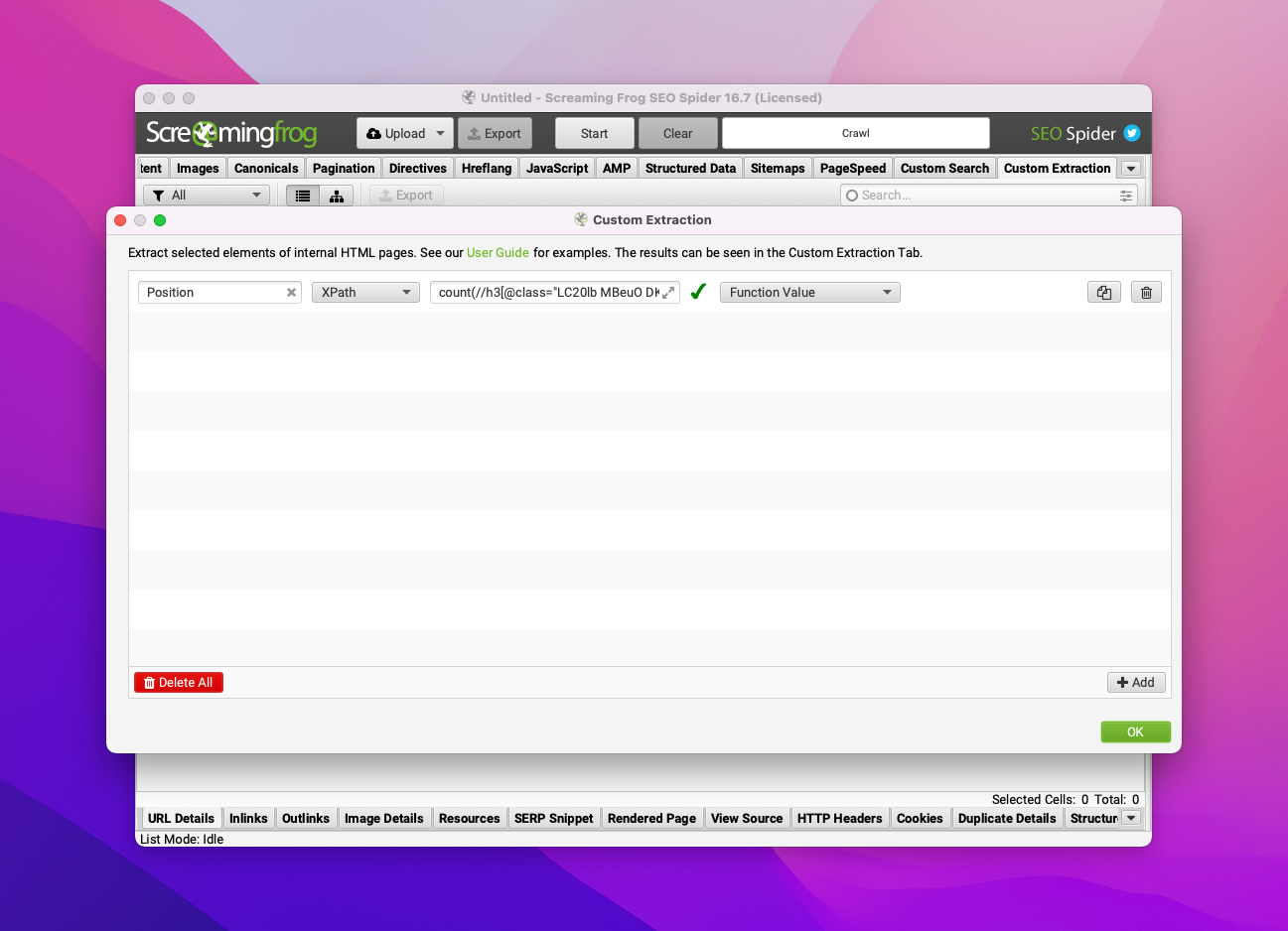
Voici l'expression XPath au complet :
count(//h3[@class="LC20lb MBeuO DKV0Md" and not(ancestor::div[contains(@class, 'related-question-pair')])]/parent::a/@href[contains(., 'antoine-brisset.com')]/preceding::h3[@class="LC20lb MBeuO DKV0Md" and not(ancestor::div[contains(@class, 'related-question-pair')])]/parent::a)+boolean(//h3[@class="LC20lb MBeuO DKV0Md" and not(ancestor::div[contains(@class, 'related-question-pair')])]/parent::a/@href[contains(., 'antoine-brisset.com')])Explications :
//h3[@class="LC20lb MBeuO DKV0Md"]: j'extrais chacun des résultats de la SERPnot(ancestor::div[contains(@class, 'related-question-pair')]): j'exclus les résultats de type "People Also Ask"parent::a/@href[contains(., 'antoine-brisset.com')]: je cible le résultat correspondant à mon sitepreceding::: je sélectionne les résultats précédents mon sitecount(): je compte le nombre de ces résultatsboolean(): si l'URL de mon site est trouvée dans la SERP, alors la fonctionbooleanrenvoietrue(1) donc j'ajoute 1 pour obtenir la position réelle de mon site, sinon elle renvoiefalse(0)
4ème étape : lancer le crawl !
Le plus dur est fait. Je peux retourner dans Screaming Frog.
J'ajoute tout d'abord l'extraction personnalisée (attention ici à bien remplacer les 2 occurrences antoine-brisset.com par l'adresse de ton site).
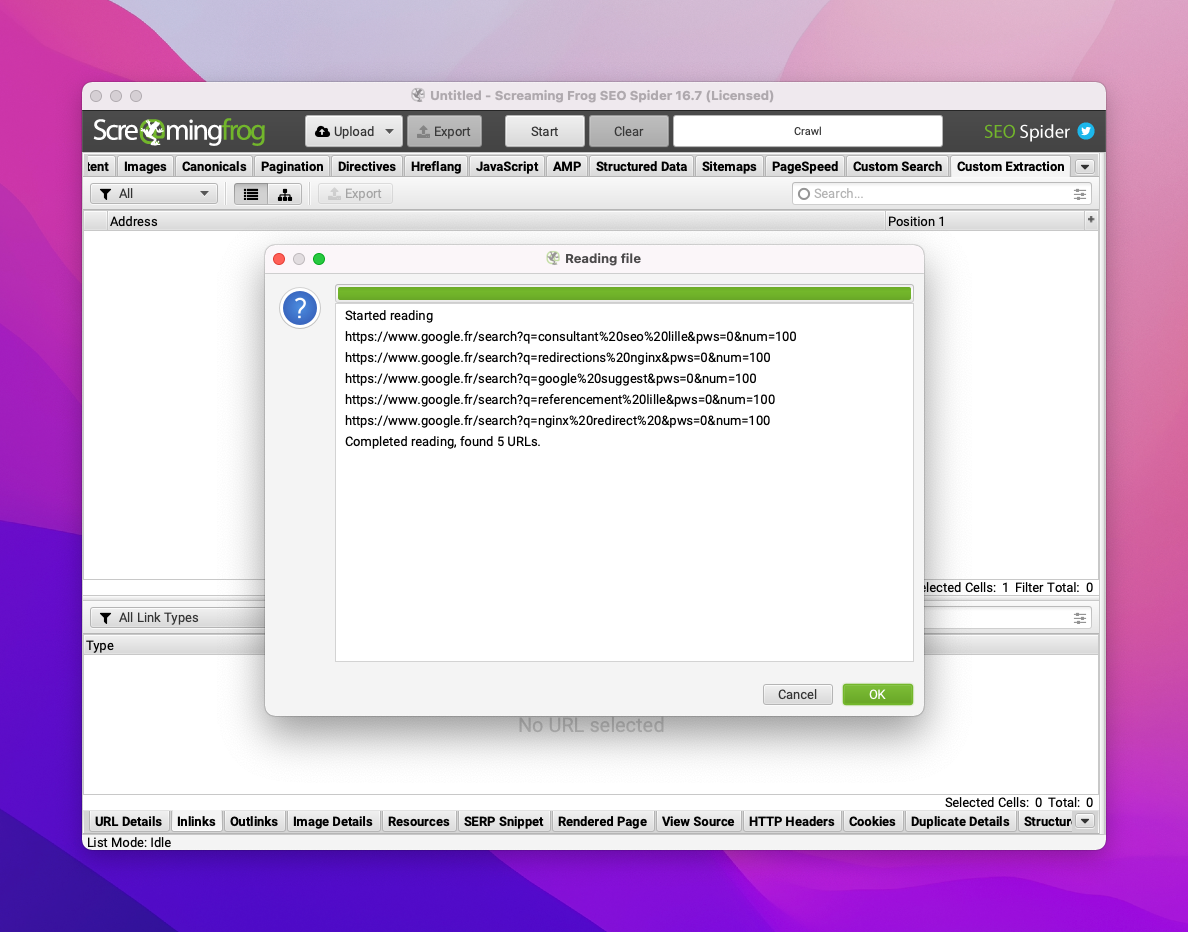
Puis je colle la liste des URLs à crawler.
Je clique sur OK et c'est parti !
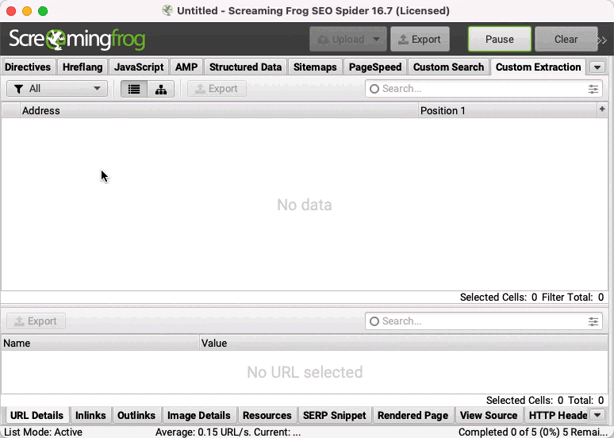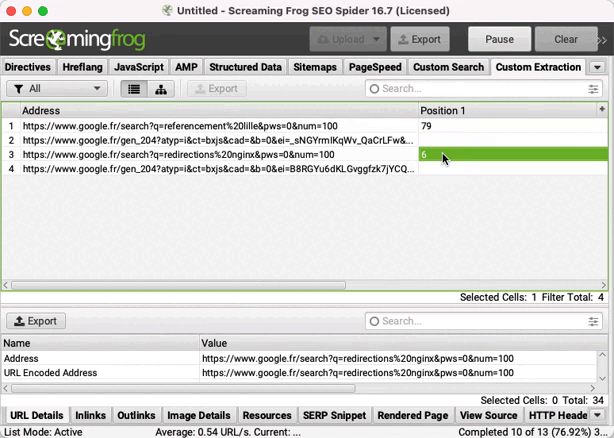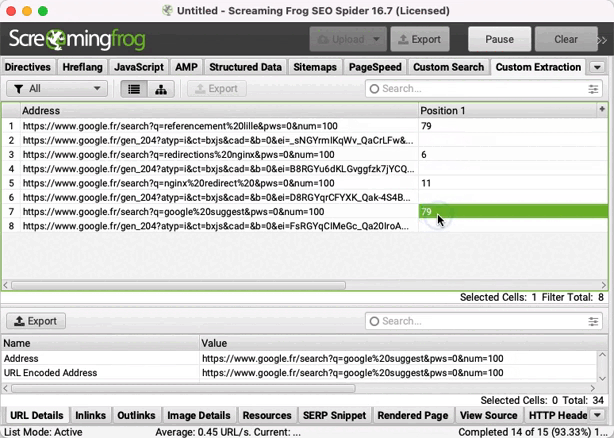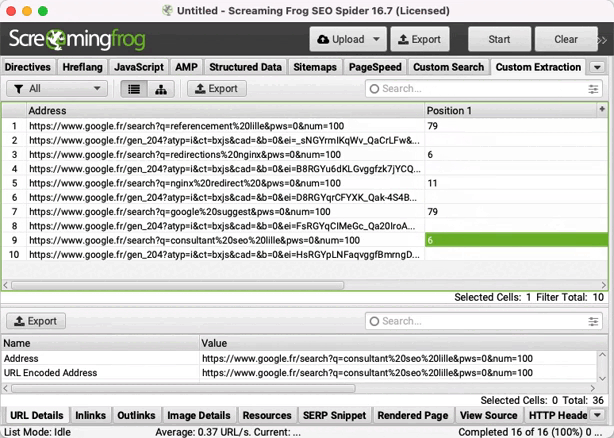
Ne tiens pas compte des URLs https://www.google.fr/gen_204?, ce sont des requêtes Google automatisées en lien avec l'historique de recherches.
La colonne "Position 1" indique la position de ton site. Si la valeur affichée est 0, c'est que tu n'es pas visible dans les 100 premiers résultats.
Voilà, il n'y a plus qu'à exporter les résultats en CSV.
Magique, non ?
Attention, je ne garantis pas que ça fonctionnera sur des centaines de mots-clés, mais pour quelques dizaines, aucun problème.
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.