
Comment catégoriser un site WordPress avec Screaming Frog ?
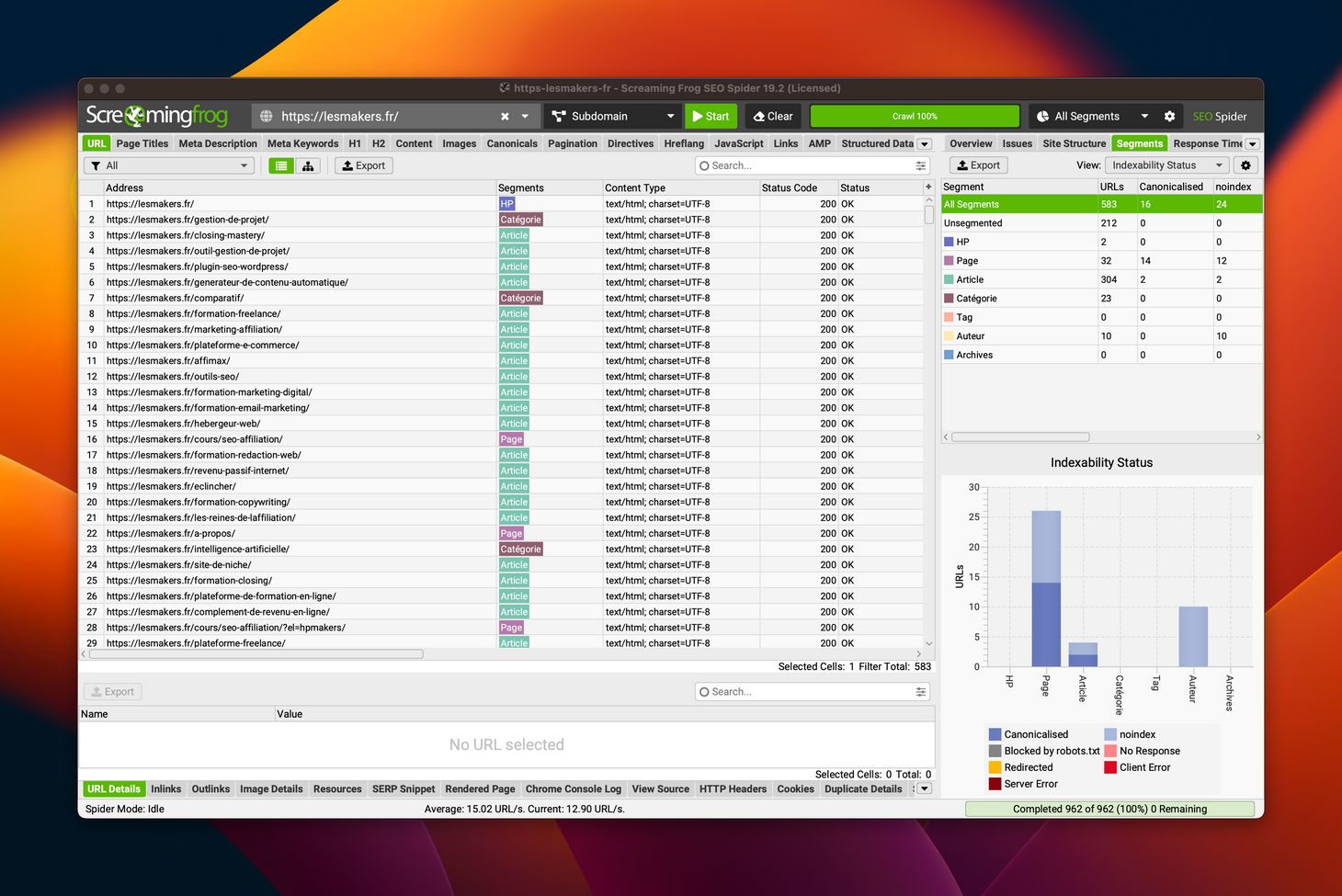
Table des matières
Depuis la version 19 de Screaming Frog, il est possible de créer des segments, autrement dit de catégoriser un site en exploitant les données extraites pendant le crawl.
Aujourd'hui, je vais te montrer comment catégoriser un site WordPress avec Screaming Frog.
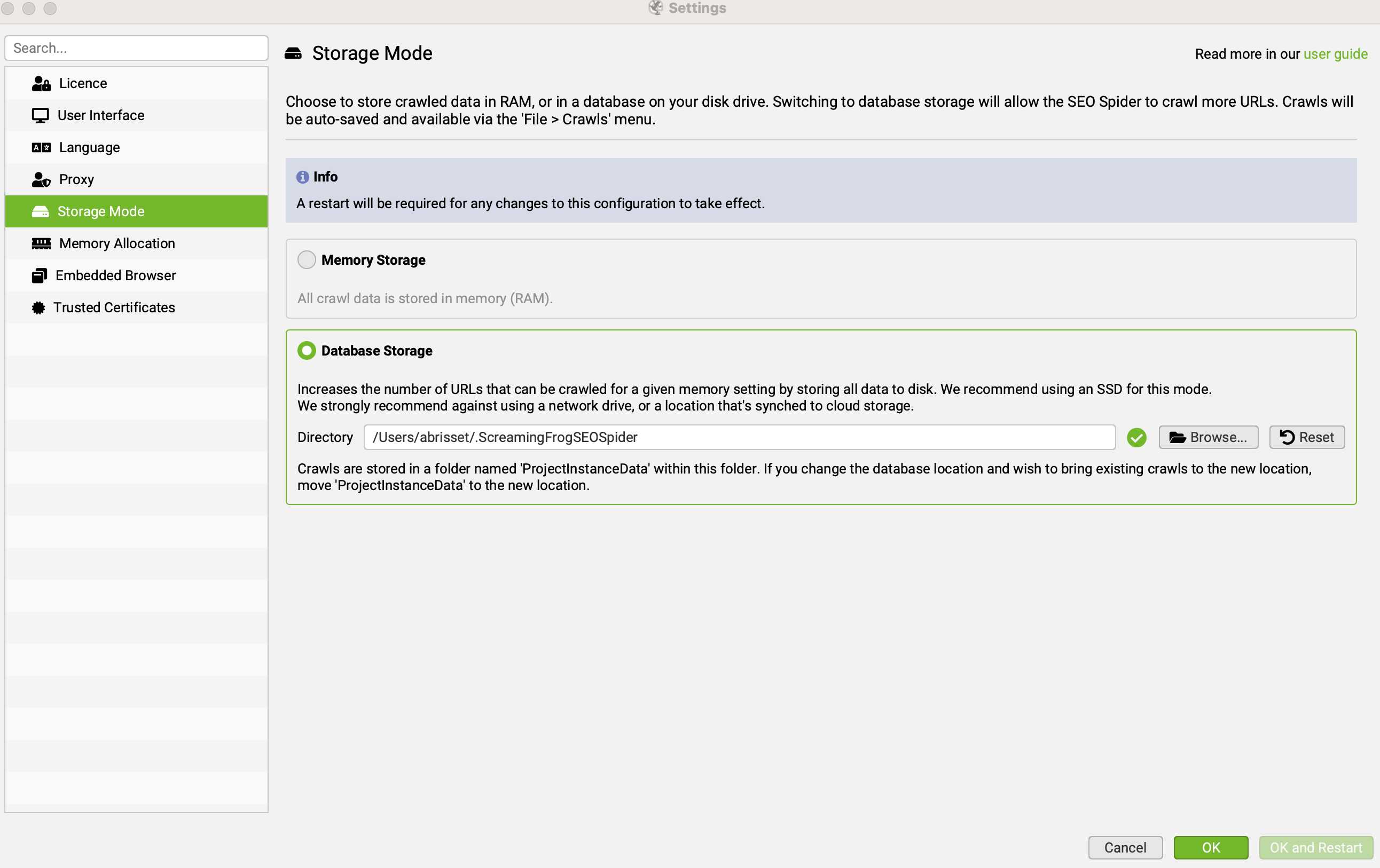
Étape 1 : passer en mode "Database Storage"
Les segments ne sont disponibles qu'en mode "base de données".
Il faut donc tout d'abord se rendre dans Screaming Frog SEO Spider > Settings > Storage mode puis sélectionner "Database Storage".
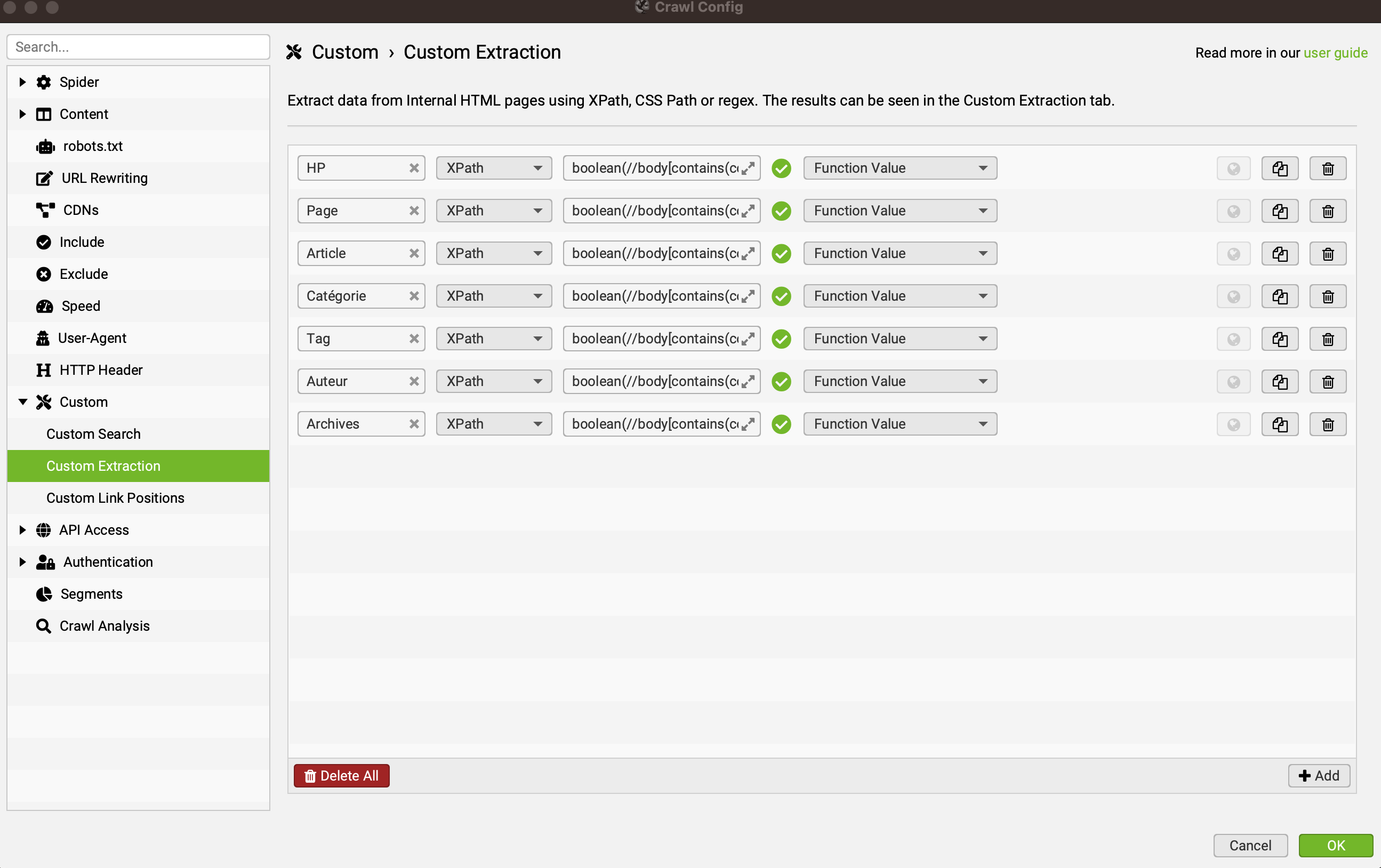
Étape 2 : créer les custom extractions
Pour déterminer à quel type de publication correspond chaque page, je vais m'appuyer sur la classe CSS du body.
En effet, sur WordPress, la balise body contient par défaut une classe CSS correspondant au template de page utilisé.
Voici les principales classes utilisées :
- "home" : pour la HP
- "page" : pour une page
- "single" : pour un article
- "category" : pour une page catégorie
- "tag" : pour une page tag
- "author" : pour une page auteur
- "archive" : pour toutes les pages d'archives (date, format, etc.)
Pour vérifier si chacune de ces classes CSS est présente dans le body, j'utilise les expressions XPath suivantes :
- HP :
boolean(//body[contains(concat(" ", @class, " "), " home ")]) - Page :
boolean(//body[contains(concat(" ", @class, " "), " page ")]) - Article :
boolean(//body[contains(concat(" ", @class, " "), " single ")]) - Catégorie :
boolean(//body[contains(concat(" ", @class, " "), " category ")]) - Tag :
boolean(//body[contains(concat(" ", @class, " "), " tag ")]) - Auteur :
boolean(//body[contains(concat(" ", @class, " "), " author ")]) - Archives :
boolean(//body[contains(concat(" ", @class, " "), " archive ")])
En gros, je me sers de la fonction boolean pour vérifier si oui (true) ou non (false) le body contient telle ou telle classe.
Je te renvoie à cet article à propos de contains pour mieux comprendre la subtilité de l'espace avant et après chaque chaîne de caractères.
Étape 3 : créer les segments
Maintenant, place à la création des segments.
Je les reprends dans l'ordre où je les ai créés.
La condition est toujours la même : Extractor (n)* — Equals (=) — true.
* Extractor (1) pour HP, Extractor (2) pour Page, etc.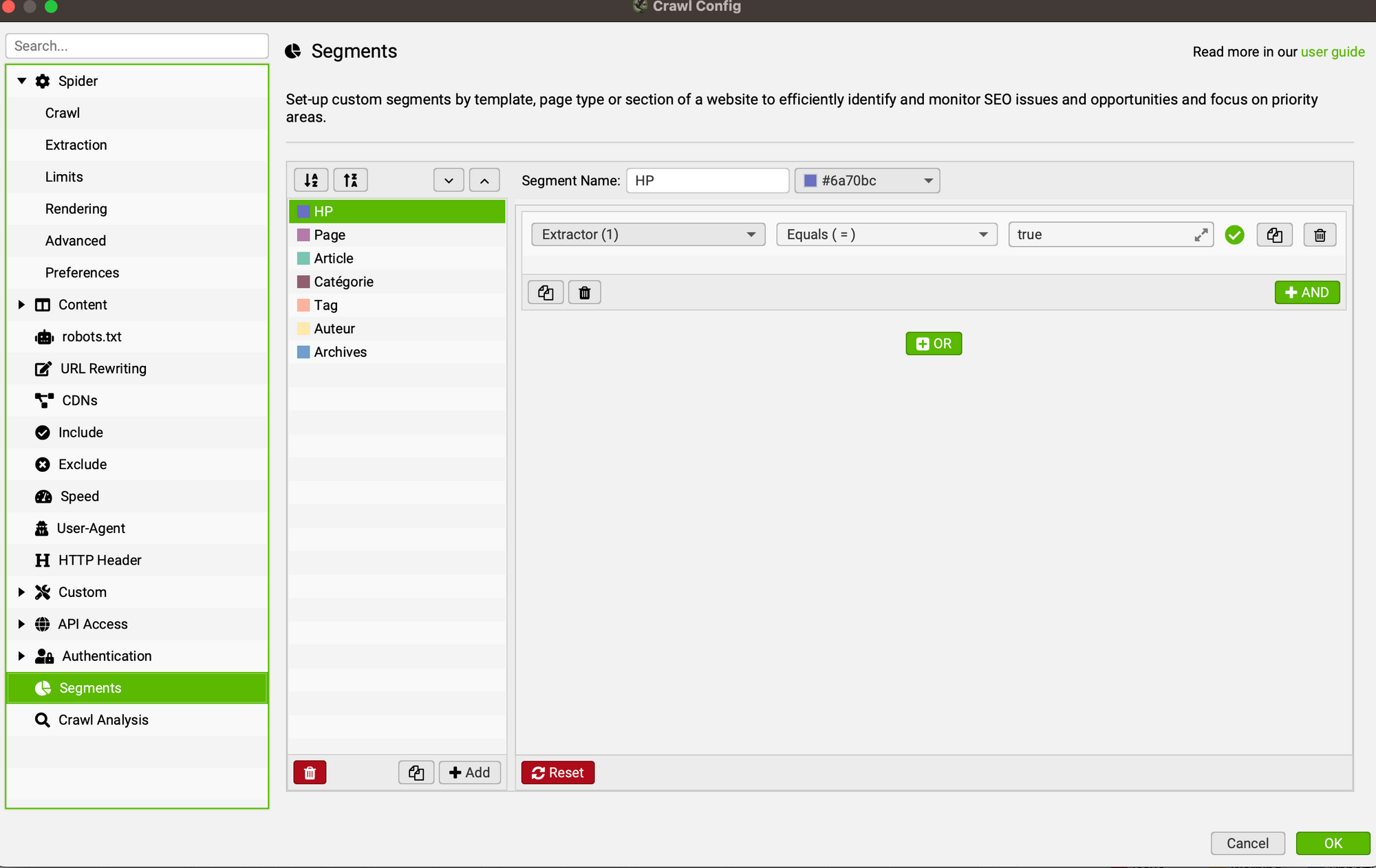
Étape 4 : crawl et analyse
Il ne reste plus qu'à lancer le crawl et à analyser les résultats une fois qu’il est terminé.
Les segments peuvent être utilisés de différentes façons :
- dans chaque onglet, une colonne segments apparaît à côté de chaque URL
- en haut à droite, un filtre est disponible pour sélectionner un segment spécifique
- dans le panneau latéral à droite, l'onglet segments permet d'afficher un certain nombre de graphiques, avec des données calculées pour chaque segment (profondeur, indexabilité, etc.)
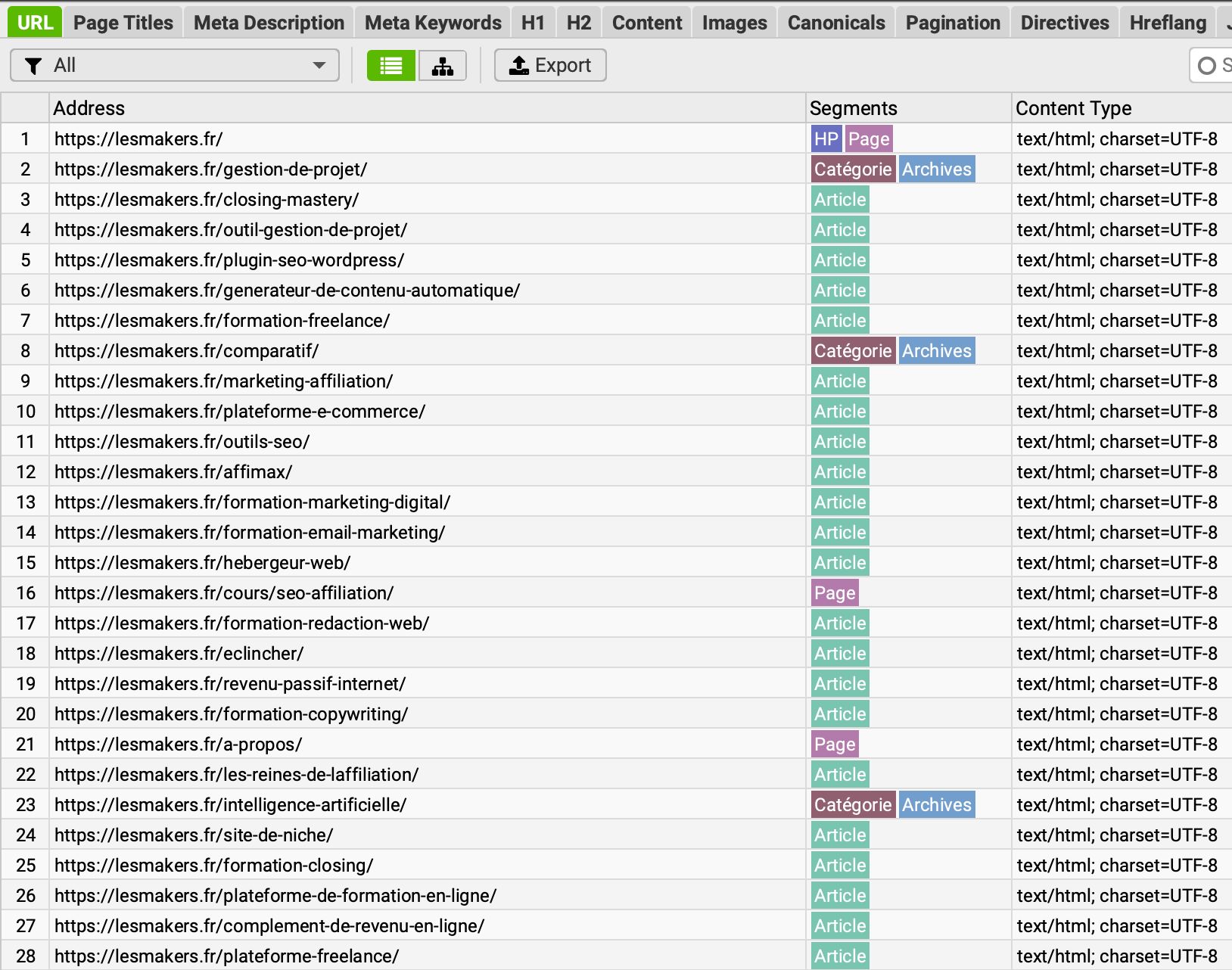
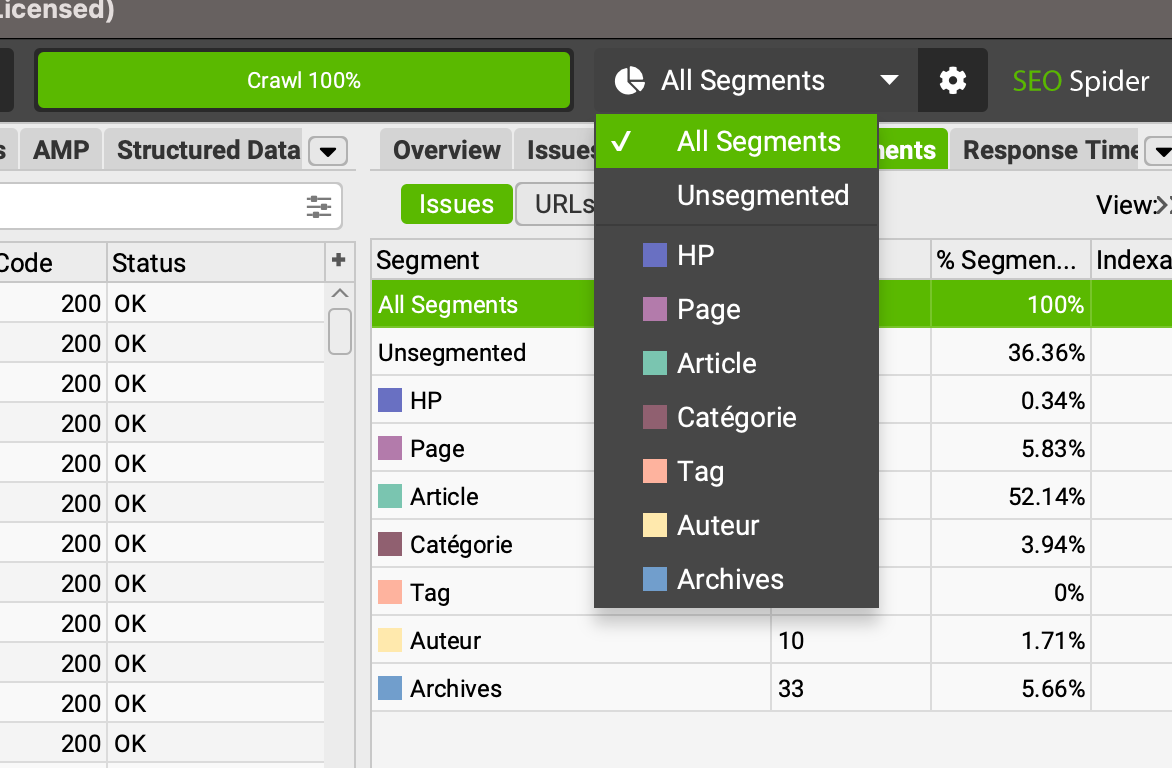
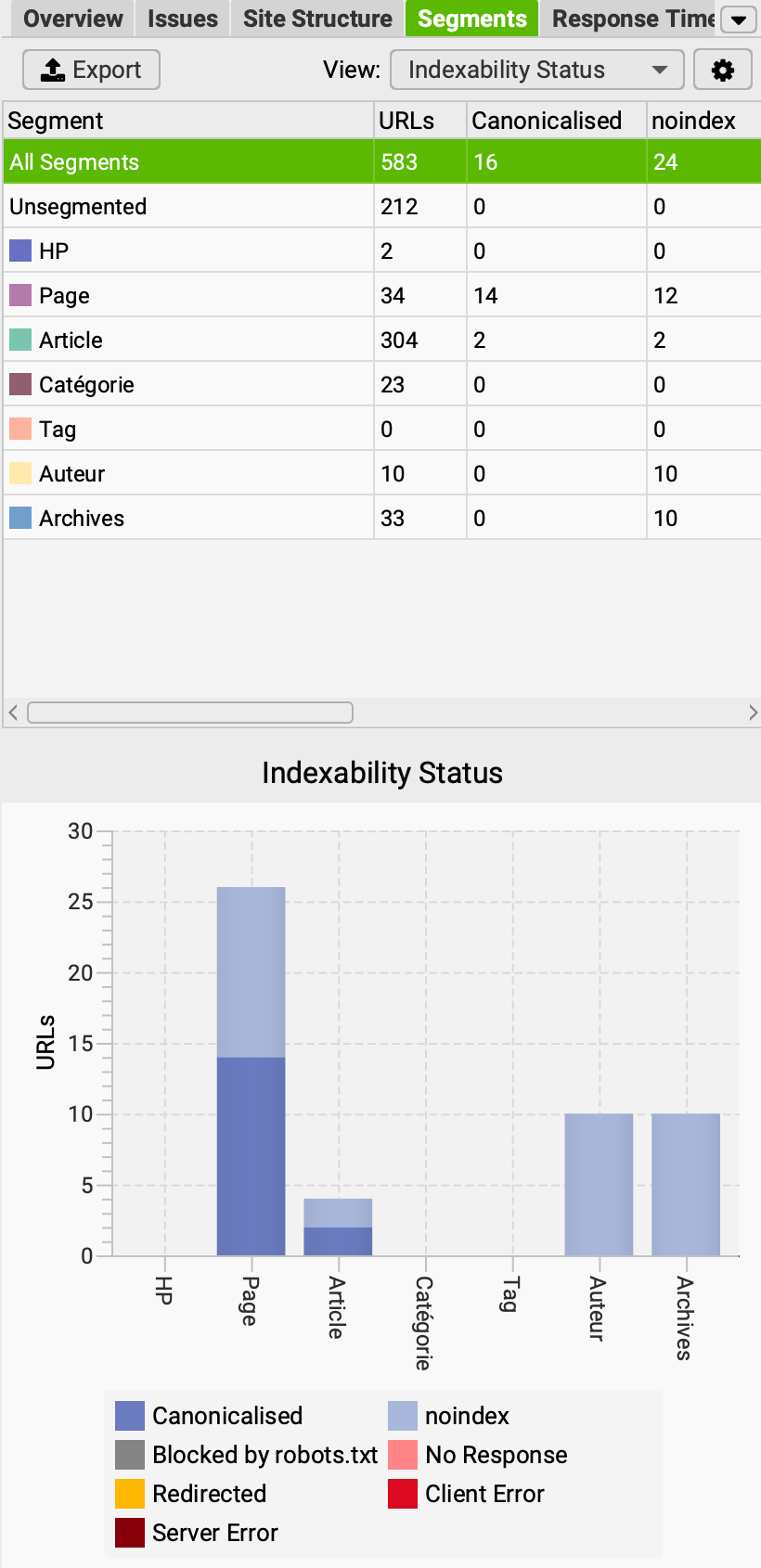
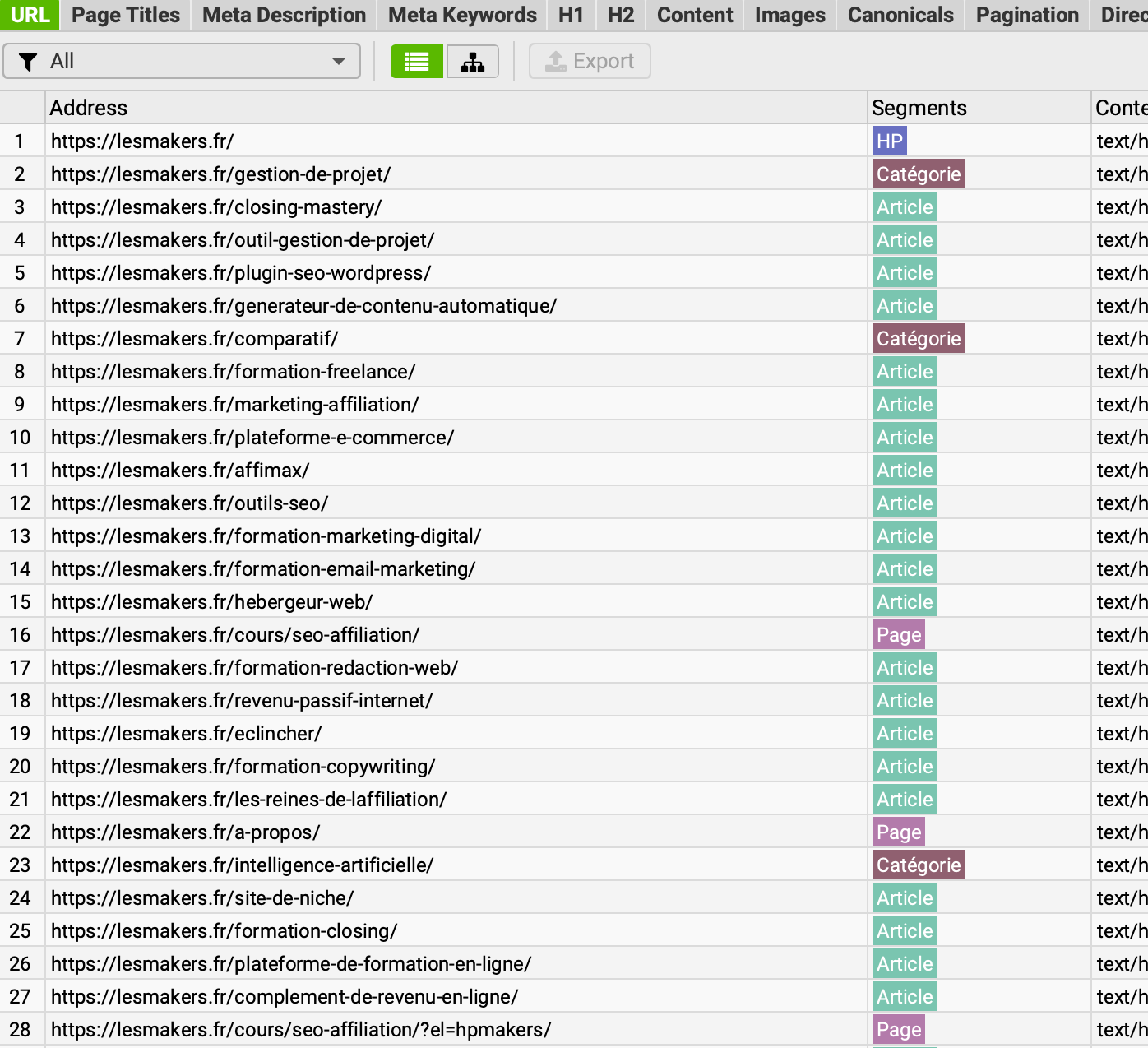
Ici, sur cet exemple du site lesmakers.fr, on peut voir que certaines URLs ont été classées dans 2 segments à la fois, ce qui signifie que mes expressions XPath ne sont pas suffisamment restrictives.
Je vais donc les modifier pour y ajouter des négations avec la fonction not.
Voici ce que ça donne :
- pour les pages :
boolean(//body[contains(concat(" ", @class, " "), " page ") and not(contains(concat(" ", @class, " "), " home "))]) - pour les archives :
boolean(//body[contains(concat(" ", @class, " "), " archives ") and not(contains(concat(" ", @class, " "), " author ")) and not(contains(concat(" ", @class, " "), " tag ")) and not(contains(concat(" ", @class, " "), " category "))])
Limites de la méthode
Si le site contient beaucoup d'erreurs 40x et 50x ou de redirections 30X, la segmentation ne donnera pas de bons résultats puisque les pages concernées remonteront toutes dans "unsegmented".
Dans ce cas, mieux vaut partir sur une segmentation "classique" en identifiant les patterns d'URL pour chaque type de page (/category/, /author/, etc.)
Même chose pour les images, les fonts, les CSS, les JS, les liens externes, etc. Ils ne seront pas ciblés par la segmentation.
Si vraiment tu as besoin de les analyser, il faudra là aussi t'appuyer sur les URLs pour la segmentation. Sinon, tu peux désactiver le crawl de ces ressources dans Configuration > Spider > Crawl.
Enfin, si tu utilises des custom post types, la configuration sera certainement à revoir.
Voilà, j'espère que ce petit tuto pourra t'être utile !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.


{kind=link}