
Extraire les liens sortants d'un site en 2 lignes de commande
Table des matières
Hier je suis tombé sur ce tweet de Paul Vengeons, qui se demandait comment récupérer rapidement les liens externes d'un site web.
Hé les SEOs, vous utilisez quoi pour checker rapidement les liens sortants (externes) d'un site ?
— Paul Vengeons (@VengeonsP) June 14, 2022
Je me permets d'invoquer : @thomascubel @Keevvn @speyronnet @onlinestratfr🎖
Dans les réponses, plusieurs outils ont été cités : Screaming Frog, Majestic, ahrefs, Babbar.tech, etc.
Du coup, je me suis posé la question suivante : comment extraire les liens externes d'un site web sans utiliser de logiciel, en exécutant une simple ligne de commande ?
J'ai donc ouvert mon terminal et je me suis replongé dans la doc de Wget, un outil qui n'est plus tout jeune (la première version date de 1996) mais qui peut encore rendre bien des services.
Combiné à Lynx, un navigateur en mode texte (sorti lui en 1992 !), c'est finalement assez simple.
Crawler le site
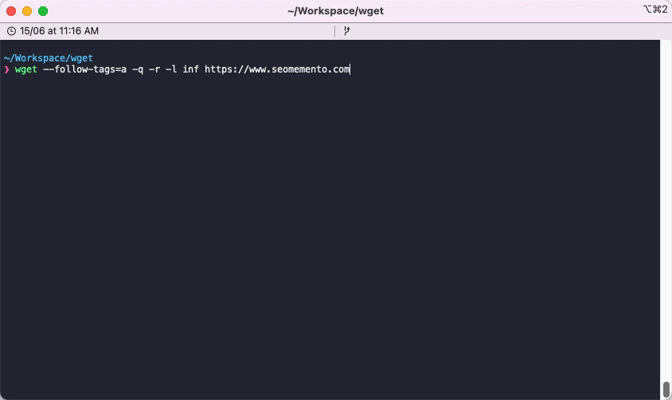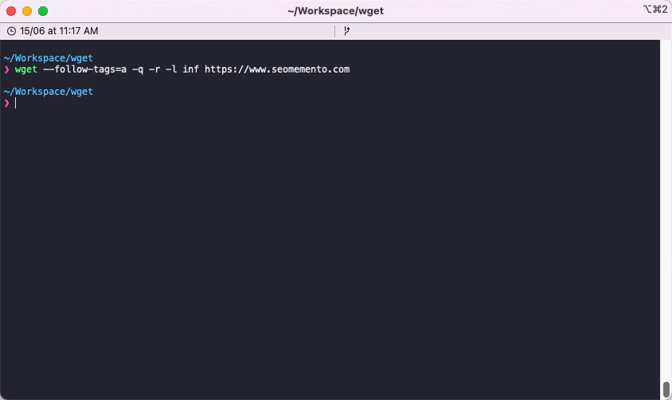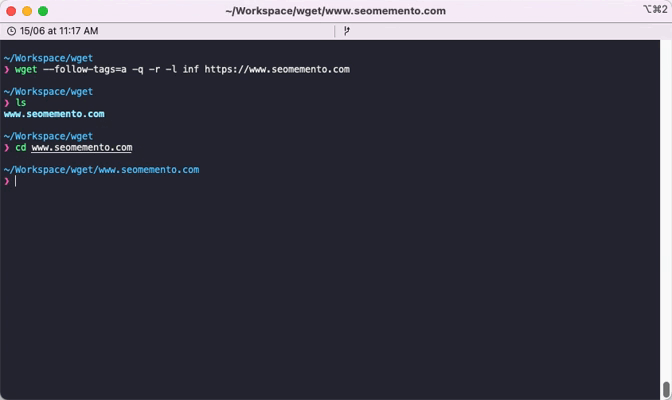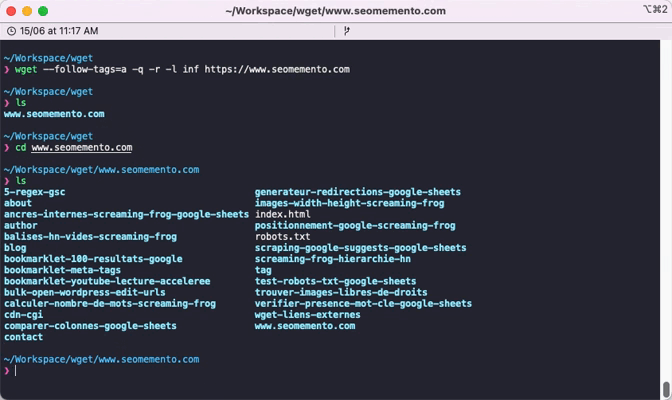
D'abord, on télécharge toutes les pages du site.
wget --follow-tags=a -q -r -l inf https://www.seomemento.comExplications :
--follow-tags=aje suis uniquement les liens a href pour éviter de télécharger les images, les scripts, etc.-q: je désactive la sortie en console-r: j'utilise le mode récursif-l inf: je ne limite pas la profondeur de crawl
Une fois l'opération terminée, tous les fichiers HTML se trouvent dans le dossier courant.
Récupérer les liens
Ensuite, on extrait les liens externes.
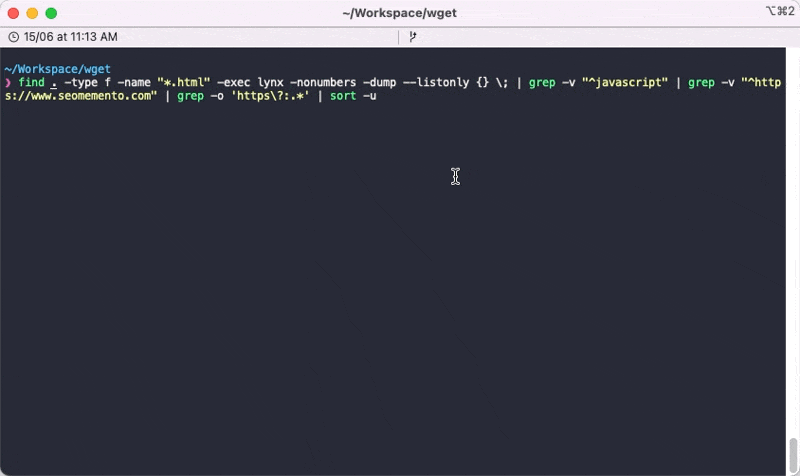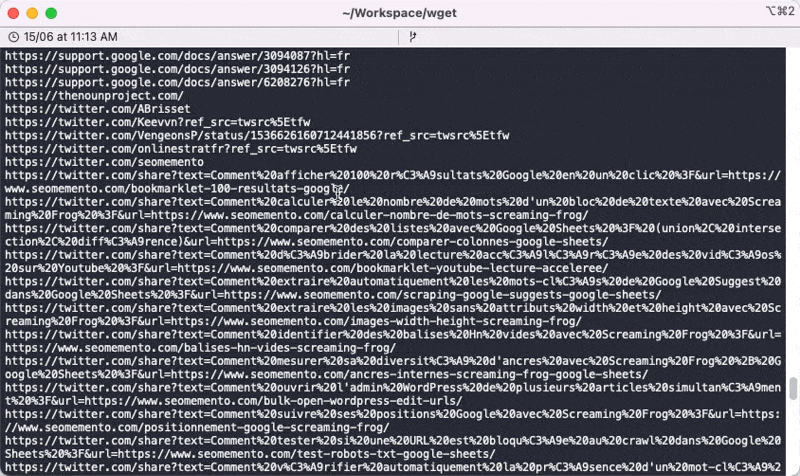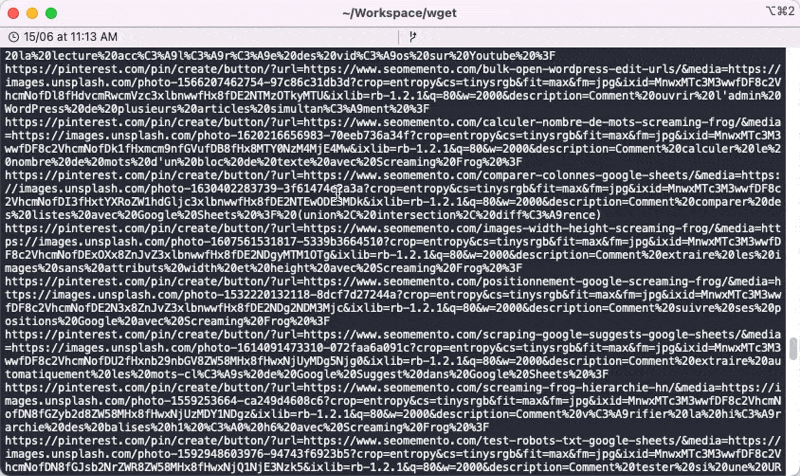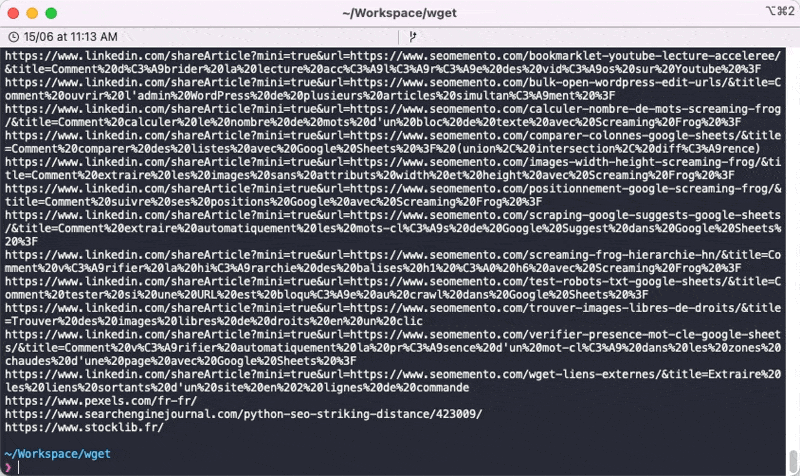
find . -type f -name "*.html" -exec lynx -nonumbers -dump --listonly {} \; | grep -v "^javascript" | grep -v "^https://www.seomemento.com" | grep -o 'https\?:.*' | sort -uExplications
find . -type f -name "*.html": je cherche dans les fichiers HTML téléchargéslynx -nonumbers -dump --listonly {} \;: j'exécute la commande lynx sur ces fichiers en retournant le résultat en console (-dump), en extrayant les liens (--listonly) et sans afficher de numéro de ligne (-nonumbers)grep -v "^javascript": je retire les lignes commençant par "javascript"grep -v "^https://www.seomemento.com": je retire les lignes commençant par "https://www.seomemento.com", autrement dit les liens internesgrep -o "https\?:.*": je ne garde que les liens commençant par "http:" ou "https:"sort -u: j'affiche les liens en les dédoublonnant et en les triant par ordre croissant
Si tu veux t'en servir à ton tour, il faudra sûrement que tu joues avec grep pour éliminer le bruit (facebook.com, twitter.com, pinterest.com, linkedin.com, etc.) et éventuellement modifier le paramètre -l de Wget s'il s'agit d'un site avec beaucoup de profondeur.
Tu peux aussi tout sauvegarder dans un fichier .txt en ajoutant > links.txt directement après la commande sort -u.
Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.


